by Daniel | Aug 28, 2017 | Data, Featured
As a way to get some more experience with various data analysis tools I needed an engaging side-project. Politics interests me, so an analysis of the publicly available Hansard transcripts from Parliament seemed like a good project.
By analysing the contents of MPs’ speeches in Parliament, I hoped to be able to get a sense of the breadth of their vocabularies (however accurate or inaccurate this might be), and see how they compare with their colleagues. By determining the total number of unique words spoken compared with the total number of words spoken for each Member, it is possible to make comparisons between the “functional” vocabularies of all MPs.
Intelligence and the size of a person’s vocabulary have long been considered analogous, however perhaps a large vocabulary merely indicates a capability or potential for sophisticated thought, rather than a direct indication of this.
There are plenty of caveats with this type of analysis, and some of the reasons why these results might not be an accurate representation of a Member’s true vocabulary are as follows:
- They could be intentionally staying “on message”
- They could be keeping their language simple to be more readily understood
- They might not want to appear pretentious
- English is a second language
- “Facts can be used to prove anything…”
- etc
There is something to be said for keeping language simple and easy to understand: this study from 2005 (with a great title) presents some interesting results about the impact of unnecessary language complexity on fluency: Consequences of Erudite Vernacular Utilized Irrespective of Necessity: Problems with Using Long Words Needlessly
The transcripts used in this project are from both the House of Representatives and Senate, from the 7th of February 2017 to the 17th of August 2017. There are 75 different transcripts, 227 Members which translated into 15.3 million words in the database. To extract only words from the transcripts, all URLs, numbers and punctuation have been removed. Word “uniqueness” is determined after a lowercase transformation, i.e. a reference to “Cash” (as in Michaelia) would be considered a match with “cash” (as in $).
It is also worth noting that verb conjugation is essentially ignored. I.e. “runs”, “running” and “ran” would be considered as 3 unique words, when in a practical sense they are the same verb.
Regardless of these potential factors, the results are interesting and presented here as is.
The total overall word count by Member gives us this:
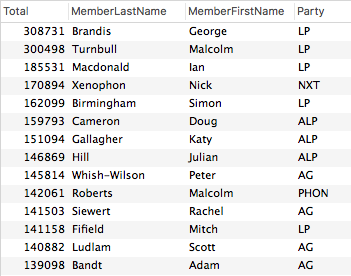
Note that Brandis doesn’t necessarily have the biggest vocabulary, he has only spoken the most words in Parliament during this period.
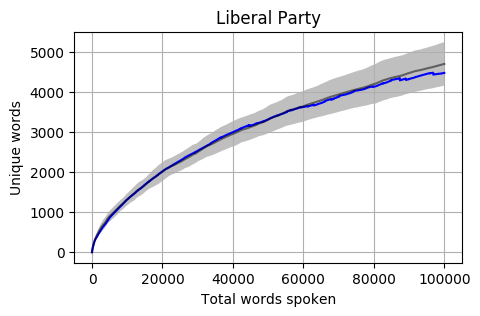
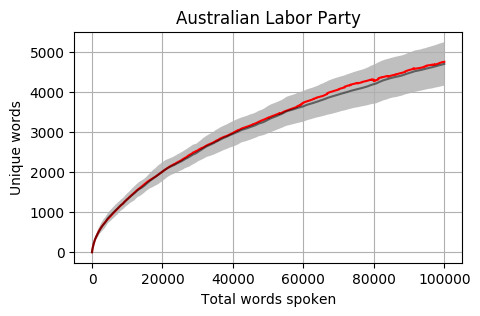
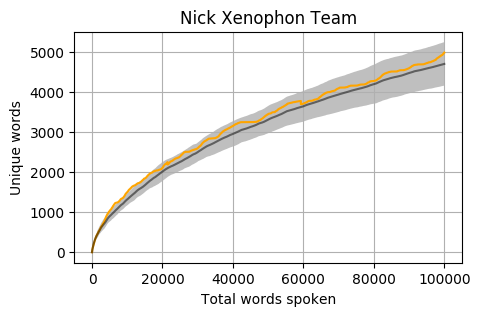
Uniqueness by total words spoken
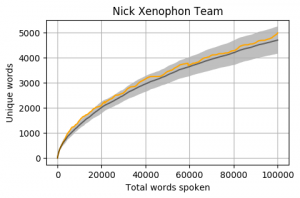
Using 100,000 spoken words as the threshold for inclusion, out of the 227 Members there are 42 from both the House of Representatives and Senate who have reached this number. If we graph the progression of the total unique word count by the total word count, we get a relatively even distribution (colours are random).

Party Colours
If we chart these same 42 Members on a bar graph using their Party colour as the bar colour a few things become apparent:
- Interestingly, at the 100K mark Malcom Roberts has the most unique words, just in front of Scott Ludlam
- The Greens are over-represented at the top – 40% of the top 5 places
- The Labor Party mean appears to be above average
- The bottom of the table is relatively heavy with Liberal Party conservatives
(Notes on the colours: all parties are their official colour apart from Australian Conservatives who are pink (sorry Bernadi), Independents who are grey and Nationals who are black, as green and yellow are both already taken)

Party by Party
Looking at the mean for each party we get the following. Note that the mean is calculated word by word and each Member’s total word count is different. When one Member is no longer part of the calculation, the overall mean can jump a little (as seen in the Liberal Party and Greens graphs).
The grey bar represents the mean for the 42 Members who reached 100,000 words. The grey area around the bar is one standard deviation from the mean.
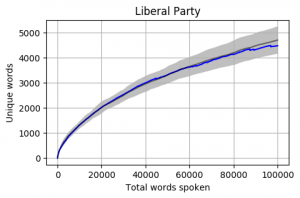
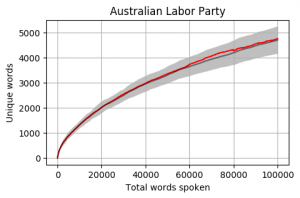
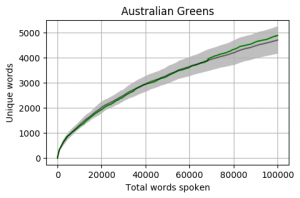
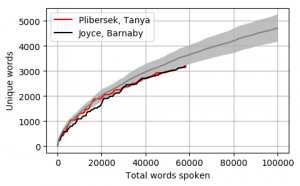
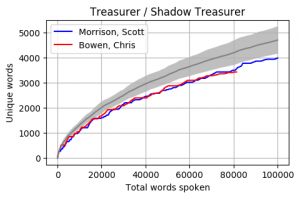
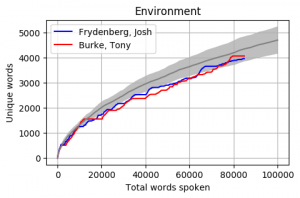
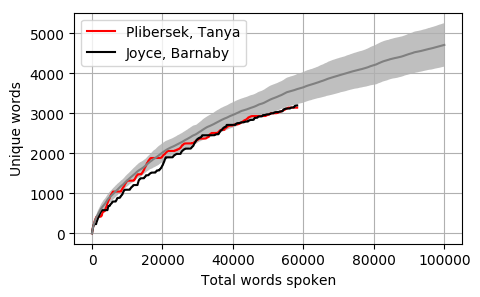
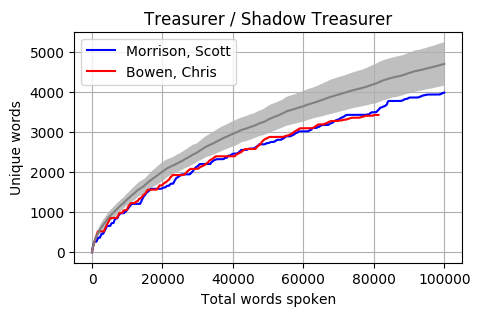
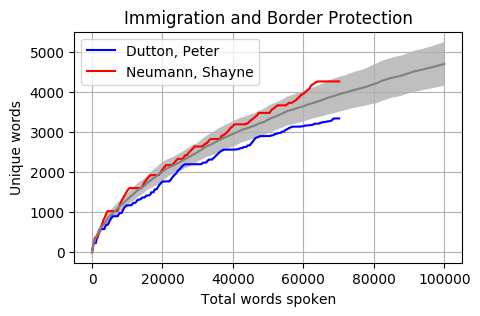
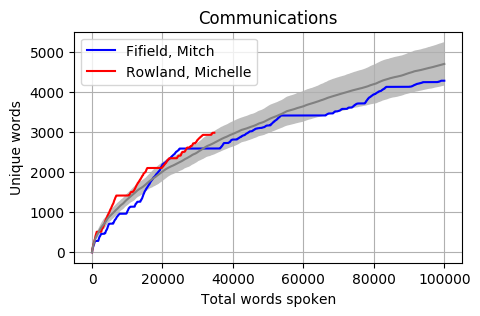
Head to head by Portfolio
Looking at Members individually gives some interesting results. Some of these Members haven’t reached the 100k mark yet however the trajectory is relatively obvious. The following graphs pit the Minister and Shadow Minister against each other for a few of the different portfolios and positions. Until I can explore the difference between speeches and answers, the impact of speechwriters on these results is unknown.

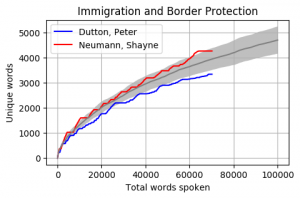

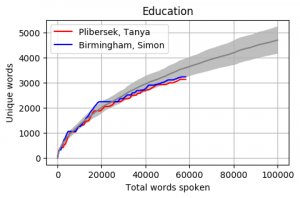
The Cabinet
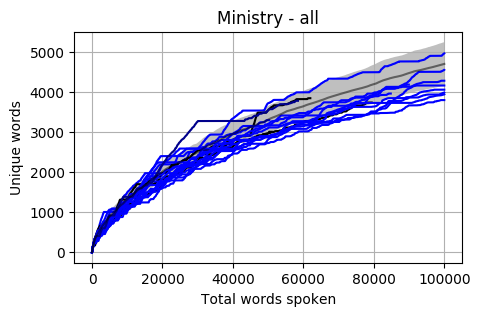
Looking at a graph of the complete Members of Cabinet the results are a little concerning. Most are below the Mean and a good proportion are also below one standard deviation.
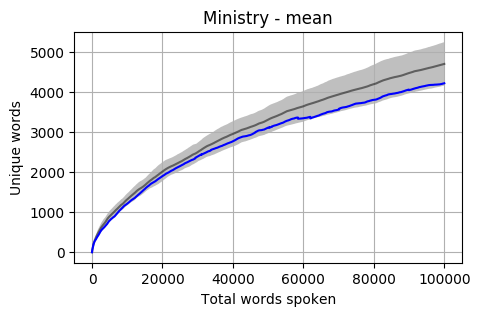
The mean of all Cabinet Members is below, and it is sitting almost at one standard deviation below the overall mean.
Up Next
There are a few other dimensions that I plan to explore in the coming weeks:
Speech context
The data is ready to segment by Speeches, Questions and Answers, and I believe that we might find some interesting differences between prepared speeches and answers that could indicate a good/bad speech writer.
Overall uniqueness
At the moment uniqueness is being judged member by member. Exploring who has the most unique words across all members (and what these are) could also be interesting.
Self reference
Could some analysis showing who refers to themselves the most (“I”, “me”, “myself”, “my”, etc) show us who is the most self-important?
Historical comparison
This data has only been for 2017. How would previous governments or cabinets compare with today?
UK Parliament
Are UK Hansard archives available in XML format?
Footnotes
This is a personal side-project unrelated to my work or employer. The accuracy of the results is not guaranteed and I could have made some fundamental errors in the code. If you have any questions, concerns, suggestions or requests please leave me a comment below.
More information about the technical process is available in this post: Hansard analysis – technical overview.
by Daniel | May 3, 2010 | actionscript, Featured
[Edit: (6th May) This case is currently under appeal, so my understanding is that no precedents have been set yet. Also it has been pointed out to me that there are other issues to consider such as qualitative test for copyright and contrary sweat of brow. Any other legal opinions are welcome.]
On the 4th of February 2010, the Federal Court of Australia ruled that the Australian Band Men at Work reproduced 2 bars of an iconic Australian round “Kookaburra sits in the old gumtree” in their hit song “Down Under”. (link to ruling)
“Kookaburra” was written in 1932 by Marion Sinclair as an entry into a competition to produce an authentic Australian folk song. It has been a campfire favourite for generations since and is sung as a “traditional” song all around the world.
But it is also a little-known fact that the rights to the song were sold after the competition in 1932 to raise funds for the Girl Guides movement and under Australian law, the song is still “in copyright”.
The brief and playful nod to the song by Men At Work did not come to the attention of the owner of the copyright of “Kookaburra,” Larrikin Music Publishing Pty Ltd, until 2007 – more than 25 years later – when this obscure piece of music trivia was featured in a quiz show. Larrikin Music then sued the band.
I’m a huge fan of the “Down Under” song and also grew up singing “Kookaburra” at kindergarten but I never made the connection either until I read about this court case.
The ruling makes interesting reading, and the judgement is based on the following assumptions about melodic copyright infringement:
- Key is unimportant: relative pitch between notes is what “makes” a melody (point 177 in the ruling)
- Tempo is not significant as long as the two versions are “more or less the same”. (point 185)
The most interesting assumption and precedent for me though is the length of melody in question.
The “Kookaburra” case is based on a single two-bar phrase. Two bars is all that is needed to prove copyright infringement.

Considering that this Kookaburra melody contains only crochets, quavers and rests (assuming a time signature of 4 / 4), there is a finite number of two bar melodies using these values.
If we divide the two bars up into ¼ notes (quavers – the shortest note value used in this melody) we get 2 bars with 8 “spaces” each:

Consider that we want to be able to include notes longer than a quaver, we must allow sustained notes, and also rests.
Using the range of one octave, and restricting the pitches to a major diatonic scale (1-8), we have 8 pitches, a value for a rest (0), and a value for a sustained note (9). This gives us 10 values to choose from for each note “space”.
Using this form of notation, the Kookaburra melody (above) would be written like this:
5555606659395030
Now we have 16 note spaces in our two bars and 10 note values which
gives 10^16 possible melodies, or
10,000,000,000,000,000 melodies.
If we play through these melodies one after the other, and each melody takes about 4 seconds to complete, our composition will take about 1268 million years. (I hope there is an interval)
The Australian Copyright Council Information Sheet states:
An original work which falls into one of the relevant categories is
automatically protected as soon as it is recorded in some way (for
example, written down, recorded on audio-tape, or saved in a digital
file). A work is “original” for the purposes of copyright law if it
has not merely been copied from another work, and it is the result of
skill or labour on the part of its author.
Obviously writing down all these melodies would be impossible, but it isn’t impossible to write a program to generate them, which is exactly what I have done.
I would say that this program is “the result of skill or labour on the part of its author” and hence is automatically protected by Australian Copyright Laws. Whether or not the code represents it being “recorded in some way… in a digital file” is another issue, but I think it probably does cover this.
This program is written in ActionScript 3.0 for Flash.
The Kookaburra two bar melody in question:

So presumably now I own the copyright of every possible (original) 2 bar one-octave melodic phrase. Give me a new song, and I’ll tell you where it already exists in my composition. This not only covers quavers, crochets and minims, but every note of length up to a breve (a double whole note). Nothing original can ever be composed again.
Speaking with my friend Chris Houston about the mathematical side of this, we realised that the beauty of using a one octave range is that with the rest and sustained values added, we have 10 choices per note position and can therefore use a base10 system to generate the melody.
This program stores the current playing melody and adds 1 to its number to generate next melody. If you start at the first melody:
0000 0000 0000 0000 (all rests and not very interesting)
the next melody will be
0000 0000 0000 0001 (a single “C” quaver at the end of the two bars, still pretty boring)
I’ve included in this program the ability to randomly generate a melody, (which is quite fun to play with and produces some interesting results) and also the ability to make it play a melody of your choice (via the address bar)
eg. http://daniel.goldsworthy.com/demo/music/?melody=1234567887654321
which will play up and down the scale.
Here are the first two bars or so from some other famous melodies:
Happy Birthday
Advance Australia Fair
Minuet in G from Children’s Bach (now in C!)
Obviously as this composition contains all of these melodies, it does infringe on many existing copyrighted works, including the Kookaburra melody, but everything that is original is now part of my composition and therefore a copyrighted melody.
The purpose of this composition isn’t to make million dollars from royalties and ruin music for everybody for the next 70 years, but to point out the flaws in the existing copyright laws. I don’t know what is right, but this ruling seems wrong.
Hopefully Larrikin Music Publishing Pty Ltd won’t be pursuing damages.
link
Thanks to:
Chris Houston for valuable mathematical input
bit-101 for the wonderful minimalcomps
John Dalziel for the time-keeping The Computus Engine




Recent Comments