Some technical details about the process for the Hansard data analysis project:
- Downloading Hansard transcripts (XML) from the Parliament of Australia website using a Python script (some Javascript hackery was required to get the proper path)
- Python with BeautifulSoup to parse the XML and write individual words to a local database, with a reference to the Member along with the context of the word (session, time, speech, question, answer, etc)
- Stripping out punctuation, numbers, apostrophe + ‘s’, URLs, etc.
- Dealing with some “interesting” data at times:
<span style="font-style:italic;">Bringing </span>, <span style="font-style:italic;">t</span>, <span style="font-style:italic;">hem </span>, <span style="font-style:italic;">h</span>, <span style="font-style:italic;">ome</span>
- Python dictionary keys to determine the ongoing unique words (and count) for each member
- Google Cloud Platform to try BigTable, BigQuery and Datalabs
- A realisation that my laptop could manage the DB and queries as long as I was prepared to wait occasionally
- Juypter Notebook
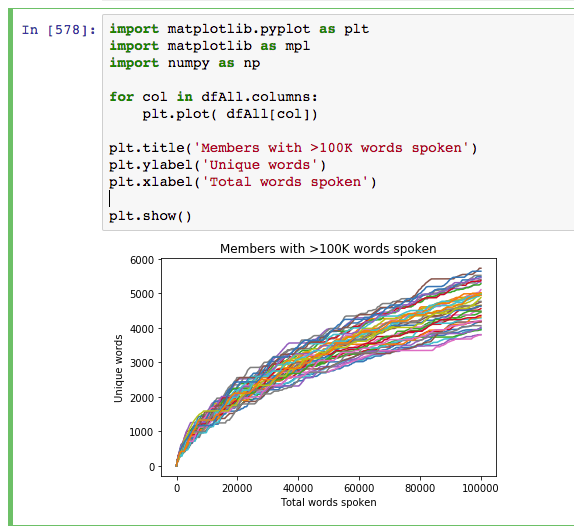
- Wrangling the data with numpy, panda and matplotlib
- Plenty of research on Stack Overflow
Recent Comments